从3DMM到stable diffusion生成式模型
为什么3dmm对3d 人脸数据还采用pca降维呢? PCA 直接基于协方差矩阵的特征分解。
问题:特征分解的结果是正向得到主成分,也就是基向量。那么从这个特征分解中,能不能得到其逆过程,也就是合成人脸3D mesh的公式呢?
从另一方面来讲,SD网络中,对输入的图片,本身就是需要做降维压缩,和3dmm其实是一样的,都是希望获得低 维度主成分的特征,因此在原理上SD的特征是2d特征,3dmm是3d特征,本质上是区别不大,是可以融合的。
何凯明的文章l-DAE(Deconstructing Denoising Diffusion Models for Self-Supervised Learning)中,
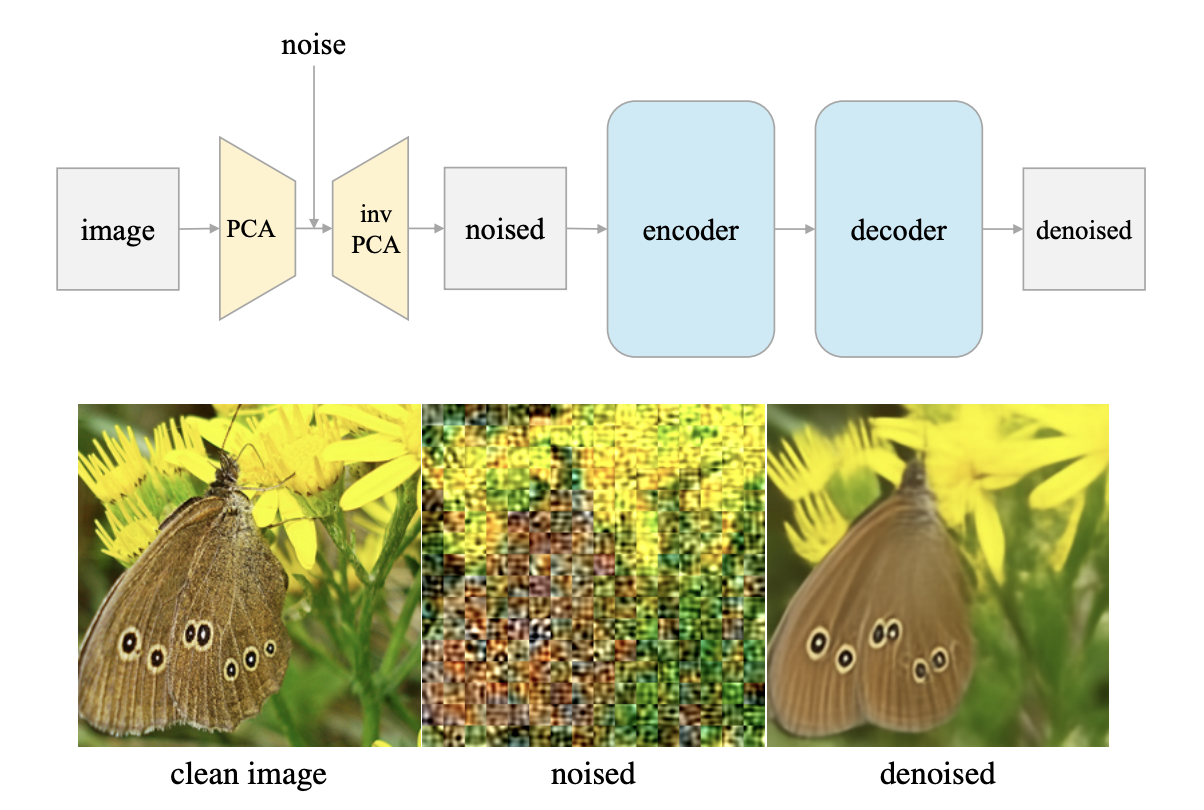
将输入图像映射到潜在空间的关键组件。 他们比较了几种不同的方法,包括卷积变分自编码器(conv. VAE)、基于块的变分自编码器(patch-wise VAE)、基于块的自编码器(patch-wise AE)和基于块的主成分分析(patch-wis PCA)。 最终发现,即使是简单的PCA也能有效地工作。 通过逆PCA(inverse PCA)将输入图像投影到潜在空间,添加噪声,然后再将噪声图像投影回图像空间。这种方法允许模型直接在图像上进行操作,而不需要tokenizer。
为什么SD模型的隐式表示需要在低维呢?
对于许多模态,我们可以将观察到的数据视为由一个相关的未观察到的潜在变量表示或生成,我们可以用随机变量z 来表示。表达这一思想的最佳直觉是通过柏拉图的洞穴寓言。在寓言中,一群人一生都被锁链锁在洞穴里,只能看到投射在他们面前墙壁上的二维阴影,这些阴影是由未观察到的三维物体在火焰前经过时生成的。对于这些人来说,他们观察到的一切实际上是由他们永远无法看到的更高维抽象概念所决定的。
虽然柏拉图的寓言阐明了潜在变量作为可能不可观察的表示来决定观察结果的思想,但这个类比的一个警告是,在生成建模中,我们通常寻求学习低维的潜在表示,而不是高维的。这是因为试图学习比观察更高维的表示是一项没有强先验的徒劳努力。另一方面,学习低维潜在表示也可以被视为一种压缩形式,并且可能揭示描述观察结果的语义上有意义的结构。然而transformer却是在高维空间进行的。能不能将两者合二为一?