被AIGC时代复活的VAE生成模型学习
VAE起源
VAE(Variational Autoencoder,变分自编码器)其实不是“新生物”,它最早出现在 2013–2014 年,由 Kingma 和 Welling 在一篇经典论文 “Auto-Encoding Variational Bayes” (2013, ICLR 2014 发表) 中提出。这篇论文首次系统化地把 概率图模型 与 深度学习的自编码器 结合起来,用 随机推断(variational inference)+ reparameterization trick 解决了采样不可导的问题,使得端到端的生成建模成为可能。
为什么在 AIGC 时代(2021–至今)又复活了?
主要原因是VAE有如下优点:
- 潜在空间压缩 (Latent space compression)
- 与扩散、流模型 (Flow) 兼容的概率建模与可控性(SD系列到现在大火FLUX系列)
- 可逆双向映射:encoder ↔ decoder
- VAE + stable Diffusion+其他微调技术,在工程实现上是友好的,聪明的工程师都喜欢个性化,所以呢,就需要能算法定制,比GAN的黑盒子有明显的工程优势。
VAE是图像生成模型的典型算法。其核心思想:将原始数据映射到一个已知分布,然后从已知分布中随机采样,通过生成模型得到与原始数据近似的数据。其本质上是对数据分布的拟合,然后从分布中采样得到新数据。
很明显,是映射分布,而不是仅仅学习分布。VAE可以生成与原始数据类似但不完全相同的数据。比如我们可以用其来生成图像、文本、音频等。具体方法为在潜在空间中随机采样数据,通过模型生成新的样本数据。VAE可以控制潜在空间(编码数据)不同维度数据的大小,使生成数据按照规则发生改变,从而扩充数据的多样性。例如,我们可以改变特征空间中人脸特征数值大小(微笑、肤色、眼镜、胡须等特征大小)而生成新样本。
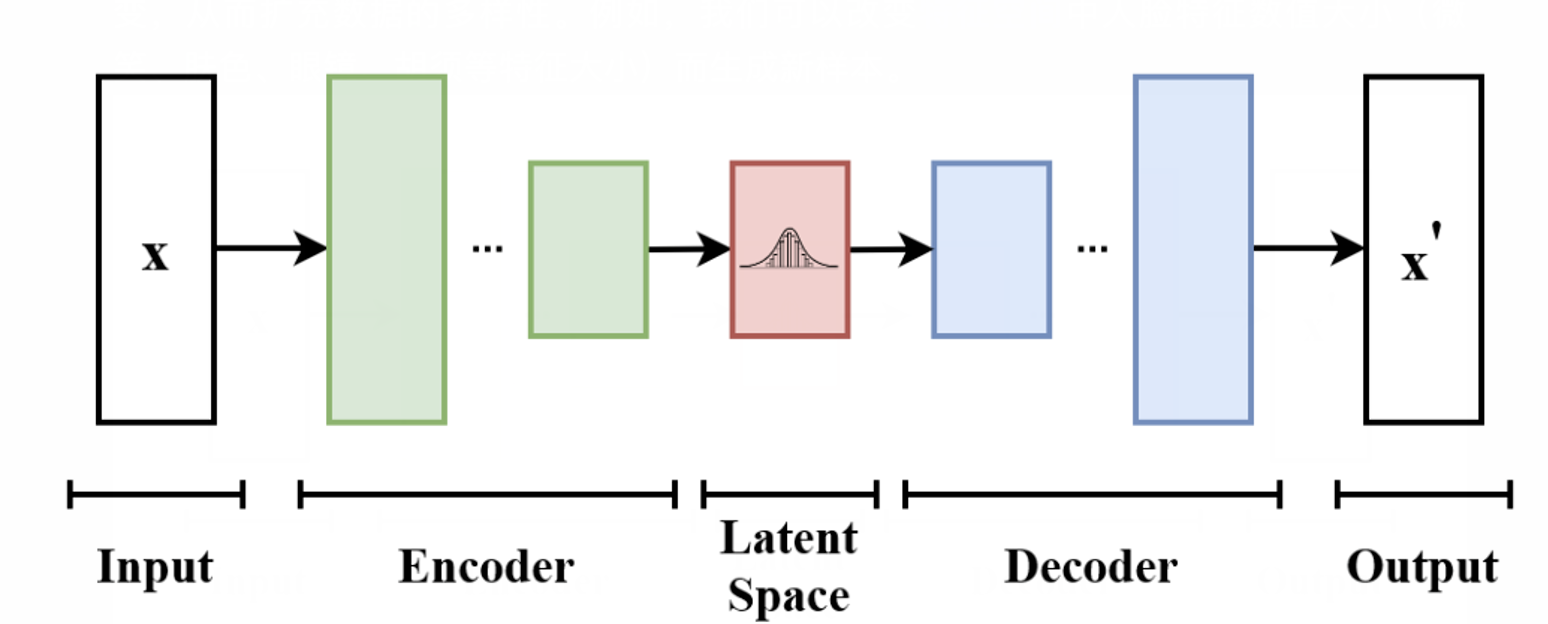
AE和VAE的区别在于编码空间的不同。AE编码值为离散值,VAE编码值为连续的数据分布。那变分的含义是什么?
VAE 之所以叫 “变分” 自编码器,是因为它使用了变分推断(Variational Inference, VI)来逼近潜在变量的后验分布。在标准的自编码器(AE)中,编码器直接输出一个固定的低维向量,而在 VAE 中,编码器学习的是一个概率分布,并使用变分推断的方法来进行优化。
VAE把数据映射到一个已知的分布,通常是高斯分布,但是不一定所有的训练集都能映射到高斯分布。
另外,我们在生成的时候,是通过在构建的分布上进行采样,经过解码器生成新的数据。假设我们在采样的时候,引进text或者image的控制信息,是不是也就会和SD+controlNet一样,实现可控生成呢?(此时先不考虑生成能力的差别)。
不管是AE还是VAE,都需要学习一个潜在变量的表示,在PCA分析中,我们也是想找到一个空间可以把当前空间下无法聚合的数据,能分开。这种类似的隐变量理论,在量子力学中也是不是有类似的作用?就是我们通过隐变量可以捕捉到显变量不能捕捉的系统性质?(隐变量-隐空间)
隐空间的存在是生成模型能进行控制的基础。对于图像而言,像素空间要进行风格,内容的控制将很复杂,像素点的聚合关系比较复杂,但是在隐空间里,由于特征表示更为解耦合了,所以进行有针对性的插值操作就方便了很多。
但是,此时的问题是:VAE和其他生成式模型里,都是压缩的形式进行编码到隐空间中,并不是相反的方向。原因之一是:隐藏表示到底是降维还是升维,主要取决于输入的数据冗余是不是很高,很明显图像的冗余信息很高,所以进行压缩实现隐空间表示。
为什么通过假设隐变量的分布 $p(z \lvert x)$ 是标准正态分布,并在实际训练中,让编码器学习到的潜在分布向标准正态分布上靠拢,就可以实现隐变量的连续分布呢?
答:每次epoch训练,我们都会在当前加载的数据上有一个 $p(z \lvert x)$ ,虽然多轮次训练,$p(z \lvert x)$ 会趋于一个整体,但是这个不能保证 $p(z \lvert x)$ 就是连续的,因为很可能 $p(z \lvert x)$ 是把每个局部的拟合分布拼接到一起,在数学上也容易理解,这样的拼接很难保证连续。如果不能连续,就没有办法进行后续的插值和采样。
分布的连续性质和微积分里的概念一致,就是如果下x1和x2距离很近,那么,他们被函数f作用之后也应该比较接近。在这里输入的图片就是x1,x2,学习的隐变量分布就是作用函数f,我们希望学习到一个局连续的f。
为什么一些有限的离散点,学习到一个连续的分布f,之后在这个连续分布上的所有点就都是有意义的呢?
因为后续需要在这个连续分布上进行采样,如果采样的没有意义,就会出现模式崩溃。
Transformer 的计算空间与隐空间的关系
| 对比维度 | Transformer | VAE / GAN / 扩散模型 |
|---|---|---|
| 计算空间 | 高维表示空间 (Representation Space) | 隐空间 (Latent Space) |
| 隐变量的概率结构 | 没有显式的概率结构 | 有明确的隐变量分布 |
| 主要任务 | 生成、变换数据 | 生成、变换数据 |
| 学习方式 | 通过注意力机制学习上下文信息 | 通过隐变量映射学习数据结构 |
| 是否可以采样? | 不能直接采样 | 可以从隐空间采样新样本 |
尽管标准 Transformer 没有显式的隐空间建模,但一些变体确实结合了隐变量建模,比如:
- VAE + Transformer(VAE-Transformer)先用 VAE 提取隐变量,再用 Transformer 建模隐变量的分布。(如文本生成任务中,使用 Transformer 处理 VAE 的潜在变量)。
- 扩散模型(Diffusion Models)+ Transformer - DALL·E 3 这样的模型用 Transformer 作为扩散模型的去噪网络,某种程度上是在隐空间上进行操作。
- Latent Bottleneck in Transformers一些 Transformer 变体(如 BERT、GPT)会用一个“瓶颈层”来强制模型学习紧凑的表示,这类似于隐空间建模。
问题:是先进行VAE降维,然后通过Transformer升维好,还是先进行Transformer升维,然后进行VAE降维好呢?哪个是合理的?
另外Transformer没有显式的概率结构,这件事的弊端是什么?是不是说明了注意力机制其实只是在离散token上构建了彼此之间的相互关系,这个离散相关关系的问题是什么?就是说注意力矩阵中的全体元素att(i,j)仅仅只能构成一个离散矩阵,无法构成一个连续分布的函数,这个的优缺点是什么?
如果站在场论的角度,我们可以通过构建一个场,或者多尺度场,来统一给出一个连续函数field(x,y),因为具备连续性了,所以采样就是可行的。能够采样的注意力的好处是什么?
1
FNet+FFT / 场论 + Fourier变换
为了降低计算复杂度,我们可以引入一个连续的场表示,定义 Token 之间的交互为一个积分方程:
\[A(x) = \int K(x, y) V(y) \, dy\]其中:
- $ A(x) $ 表示 $ x $ 处的注意力响应
- $ K(x, y) $ 是 $ x $ 位置受到 $ y $ 位置影响的“场强”
- $ V(y) $ 是 $ y $ 位置的特征信息
- 积分替代了离散求和,使得计算复杂度降低
这个方程类似于电磁场、引力场的计算方式:
\[F(x) = \int \rho(y) G(x, y) \, dy\]其中 $ G(x, y) $ 是 Green’s function,描述场的传播方式。
2026-03-16-note
1) LLM 所建模的对象是离散的语言,离散化建模,就意味着不支持连续采样;
SD 又采取的是连续建模,支持连续采样。
多模态融合中假设包含离散信息,连续信息,怎样才能将离散信息与连续信息进行混合?
强行把图像离散化,仿照LLM 自回归的建模,有什么问题?