训练阶段空间上的ResNet与推理阶段时间上的KV Cache
训练阶段空间上的ResNet-可增量认知学习
ResNet的本质: 残差网络背后的策略是让网络去拟合残差映射,而不是让层去学习底层的映射。
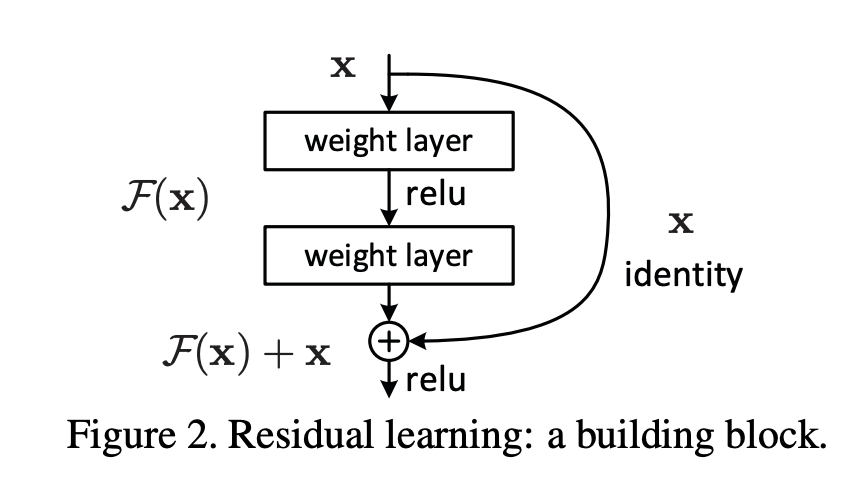
最先提出该网络是何恺明的革命性的文章:
为什么要如此呢?我们这里不推导数学公式。在直观上来看,CNN里的非线性激活层是问题的关键。
- 为什么我们要使用非线性激活而不是线性激活呢?
从字面就可以知道,我们面对的大多数特征线性的很少,线性激活无法刻画非线性系统特征,而且这个世界本身就是非线性的,线性只是很少特例,神经网络要能反映现实,必须要引进非线性。
假设一个两层网络:
第一层:$a_1 = w_1 x + b_1$
第二层:$a_2 = w_2 a_1 + b_2 = (w_2 w_1) x + (w_2 b_1 + b_2)$
可简化为 $a_2 = w’ x + b’$ ,与单层线性模型无异。
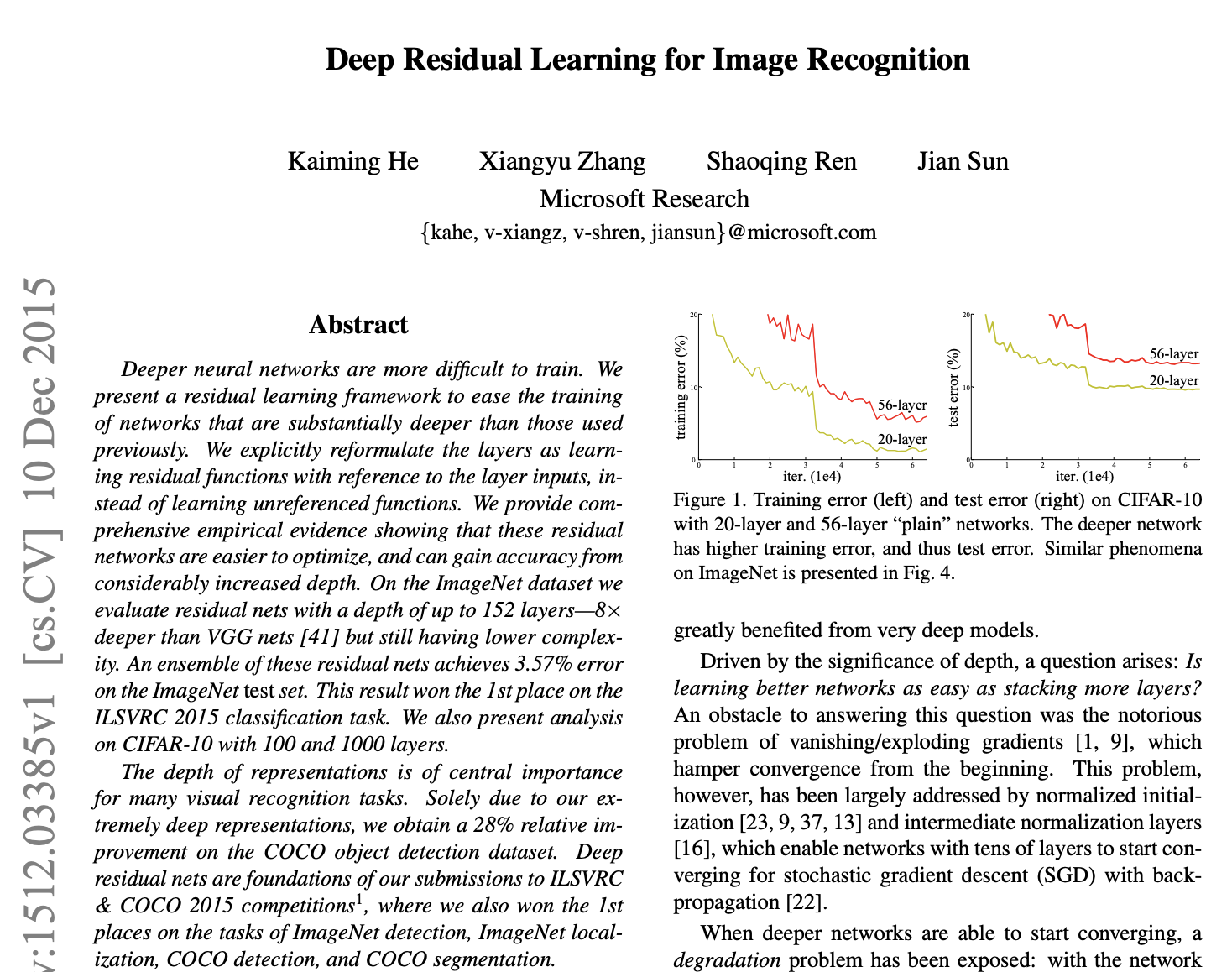
使用了非线性激活层,就完美了吗?也不是的,一个输入特征被非线性化的激活层作用后,人们发现当模型层数增加到某种程度,模型的效果将会不升反降。也就是说,深度模型发生了退化(degradation)情况。原因就是在加深网络时,训练出现“梯度爆炸/消失(弥散)”。
梯度消失 → 浅层参数停滞 → 模型无法学习基础特征 → 性能下降似“遗忘”;
梯度爆炸 → 参数剧烈震荡 → 模型无法稳定逼近最优解 → 表现波动似“偏离”
数学上累积乘法是可以明显得到这个结论的。梯度是什么?梯度是模型优化时的地图路径指南,梯度消失就是我们的地图路径,一开始就比较谨慎,担心错过目标点,所以就谨小慎微,谨慎到一定程度,就最后停滞不前,一直在一个平台上被滞留,无法驱动下降到最优目标点(就像人一样,如果过于谨慎,就无法抵达目标);梯度爆炸就是一开始,我们就是“冒险激进狂”,有一口吃一个胖子的想法,导致我们的地图路径坡度很大,路径险峻,恰好命中模型最优目标点的概率也很低(就像人一样,如果过于激进冒险,就无法击中目标,容易在真实目标周围震荡,也像用菜刀雕刻木雕)。
- 我们应该怎样做呢?
一个直观的办法就是,我们要在地图路径上设置‘途经点’,就是小步快跑的哲学,我们在当前步骤有一个小目标,就可以避免过于谨慎和过于激进的问题。ResNet 的每一层不是直接承担“到目标的全程”,而是“不断修正前一层的不足”;最后所有残差修正的累积,就是网络整体逼近任务目标的方式。
因此,ResNet 网络不是去拟合比如 $ H(x) $ 这样的初始映射,而是去拟合 $ H(x) - x $ 这样的残差映射。
关于初始映射,$ x \to H(x) $,我们数学直观有两种方式:
就是直接的映射,找到 $ H(x) $。
另一种直观是,我们没有经过映射网络之前是 $ x $,经过之后是 $ H(x) $,在串式连接下,即就是:
\[\begin{aligned} x_1 &\to H_1(x_1): \quad \text{得到 } H_1(x_1),\text{ 此时的 } H_1(x_1) \text{ 又被当做输入参数,送入下一步的网络中,} H_1(x_1) \text{ 又被当作 } x_2; \\ x_2 &\to H_2(x_2): \quad \text{得到 } H_2(x_2),\text{ 此时的 } H_2(x_2) \text{ 又被当做输入参数,送入下一步的网络中,} H_2(x_2) \text{ 又被当作 } x_3; \\ &\quad \vdots \\ \end{aligned}\]依此类推。
由此我们可以看到,如果以“途经点”监督的方式,其实 $H_i(x_i)$ 也是可以看作输入变量的,那么 $x_i \to H_i(x_i)$ 的映射就有了新的理解,我们其实可以问, $x_i$ 经过 $H_i$ 映射之后,站在特征演化的角度来考虑,输入参数变化是多少?也就是一阶差分是多少?就是说这个当前的映射网络所产生的影响是什么?
即就是 $ F_i(x_i) = H_i(x_i) - x_i $,这也是一个残差主干网络所要做的事情。从而 $ H_i(x_i) = F_i(x_i) + x_i $ 。
任何一个函数都可以表示为 $H(x)=F(x)+x$ 的形式,在动力系统角度是可信的。由于我们需要构建的是一阶差分,实际上是特征演化速度场的一个简化。
在动力系统角度:
层索引 $ n $ 类似时间步,残差 $ F(x_n) $ 类似微分增量。则:
\[\frac{dx}{dn} = F(x)\]和目前AIGC领域大火的流匹配模型(Flow Matching Model)有异曲同工之妙,流匹配模型的核心思想是:给定一个初始分布 p0 和目标分布 p1, 想要学习一个 连续时间流(Continuous Flow),即随时间 $ t \in [0,1] $ 从初始分布变换到目标分布,表示为微分方程:
\[\frac{dx}{dt} = v(t, x)\]其中 $ v(t, x) $ 是速度场或流向量场。
以上关于映射的理解(2)对KV cache优化有一定的启发意义。KV cache优化可以看作是在推理时,在时间维度下的一种优化技术,就是基于残差的思想。残差网络的学习任务本质上是学习增量变化,属于增量感知的策略,小步快跑,所以有效。
推理阶段时间上的KV Cache-可增量认知推理
在Transformer自回归生成过程中,大模型推理性能优化的一个常用技术是KV Cache,该技术可以在不影响任何计算精度的前提下,通过空间换时间思想,提高推理性能。历史token的Key/Value向量是固定不变的。KV Cache通过缓存这些中间状态,避免对已生成序列的重复计算。其本质是时间维度上的信息复用——新token生成时直接复用历史计算结果,而非重新推导。时空的相对性–在算法上的体现。每 step 内,输入一个 token序列,经过Embedding层将输入token序列变为一个三维张量[b, s, h],经过一通计算,最后经logits层将计算结果映射至词表空间,输出张量维度为[b, s, vocab_size]。
当前轮输出token与输入tokens拼接,并作为下一轮的输入tokens,反复多次。可以看出第i+1 轮输入数据只比第i轮输入数据新增了一个token,其他全部相同!因此第i+1轮推理时必然包含了第 i 轮的部分计算。
Hungging Face对于KV Cache的实现代码在transformers/models/gpt2/modeling_gpt2.py 文件中的GPT2Attention中实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
def forward(
self,
hidden_states,
layer_past=None,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
use_cache=False,
output_attentions=False,
):
if encoder_hidden_states is not None:
if not hasattr(self, "q_attn"):
raise ValueError(
"If class is used as cross attention, the weights `q_attn` have to be defined. "
"Please make sure to instantiate class with `GPT2Attention(..., is_cross_attention=True)`."
)
query = self.q_attn(hidden_states)
key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)
attention_mask = encoder_attention_mask
else:
query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
# KV Cache
if layer_past is not None:
past_key, past_value = layer_past
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
if use_cache is True:
present = (key, value)
else:
present = None
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)
attn_output = self.c_proj(attn_output)
attn_output = self.resid_dropout(attn_output)
outputs = (attn_output, present)
if output_attentions:
outputs += (attn_weights,)
return outputs # a, present, (attentions)
【小结】
这些算法设计的本质,归根结底在于对信息冗余的巧妙利用与权衡。
空间换时间:通过引入存储冗余(如缓存、预计算结果),避免重复计算,从而显著减少运行时间。
典型代表:动态规划(DP)、记忆化递归(Memoization)。时间换空间:主动舍弃存储资源,允许重复计算以节省内存占用。
典型代表:递归算法、回溯算法(Backtracking)、Fibonacci 流式生成器等。
二者本质是对“冗余”的不同取舍——
一种是存储冗余换取计算效率,
另一种是计算冗余换取空间节约。
在实际工程中,选择何种策略,取决于具体场景下的性能瓶颈:是受限于内存?还是对响应速度有严苛要求?
【20260317-note】
1)最近看到Ilya Sutskever 说过:
“LSTM is a ResNet rotated 90 degrees.”
本质是在说:
1
LSTM 和 ResNet 在“信息流结构”上是同一种东西,只是展开的维度不同。
LSTM 在做什么(时间方向-简化版):
\[c_t = f_t \cdot c_{t-1} + i_t \cdot \tilde{c}_t\]其中:
- $c_t$: memory(状态)
- $f_t$: forget gate
- $i_t$: input gate
| ResNet | LSTM |
|---|---|
| ($x_{l+1} = x_l + F(x_l)$) | ($c_t = c_{t-1} + \text{update}$) |
| 沿“层”传播 | 沿“时间”传播 |
| skip connection | memory connection |
“旋转90度”到底是什么意思?
ResNet 是沿深度展开的“非共享参数的残差迭代系统” LSTM 是沿时间展开的“共享参数的递归动态系统”。
ResNet 解决:深层网络梯度消失
LSTM 解决:长序列梯度消失
解决办法都是提供一条“恒等路径”让梯度直接传播。
2)Kimi 近期文章Attention Residuals: 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔
重新思考深度聚合。
残差连接长期以来依赖于固定、均匀的累积。受时间和深度二元性的启发,我们引入了注意力残差,用学习到的、与输入相关的、基于前一层的注意力来取代标准的深度递归。
- 引入 Block AttnRes,将层划分为压缩块,使跨层注意力在规模上切实可行。利用注意力机制回头去评估前面所有层的产出,按需提取真正有用的信息。逐层回头看太费内存和通讯成本了 。所以作者设计了分块注意力残差(Block AttnRes),把网络切分成几个区块,后续的层只需要看前面区块的“浓缩总结”,完美解决了算力和内存的瓶颈。
- 可作为高效的直接替换方案,展现出 1.25 倍的计算优势,而推理延迟开销可忽略不计 (<2%)。
一句话总结:Transformer 已经用 attention 解决“token 选择”,现在用 attention 解决“layer 选择”。
3)2025年7月文章
DeepCrossAttention: Supercharging Transformer Residual Connections
深度交叉注意力机制能够实现不同深度层之间更丰富的交互。和上面的Attention Residuals思想咋之像呢?DeepCrossAttention文章看起来理论论证更多一点。
把“层”当成“token”做 attention

猜测:或许结合我的上面的ResNet 与 KV Cache博文,我们不仅仅可以在算法原理上思考,也可以在计算范式上思考,进而在状态机角度进行计算效率优化,借鉴SSM/Mamba。