从“听见红色”,巴甫洛夫条件反射实验,RL时序差分算法,到LLM“看”懂图像
1.统一世界模型
在人类感知经验中,我们看到红色、听到红色,在大脑中会形成统一概念,指向同一个“红色”概念,这里红色可以换为其他任何感知对象,道理是一样的。人类的大脑就是一个统一强大的世界模型:你闭眼也能想象“打碎玻璃的声音”、“踩在雪地上的触感”。
2.神经认知现象-联觉(Synesthesia)
联觉是一种神经认知现象:当一种感官或认知通路被激活时,自动且不可控地引发另一种感官体验。例如:高音 ↔ 明亮/浅色低音 ↔ 昏暗/深色.
| 表达 | 感官转换 | 效果 |
|---|---|---|
| 甜美的歌声 | 味觉(甜)→ 听觉(歌) | 形容声音悦耳、令人愉悦 |
| 刺耳的噪音 | 触觉(刺)→ 听觉(噪音) | 强调声音尖锐、令人不适 |
| 温暖的笑容 | 触觉(暖)→ 视觉/情感(笑) | 传递亲切、友善的情感 |
| 冰冷的目光 | 触觉(冷)→ 视觉(目光) | 表现疏离、冷漠 |
| 芳香四溢的画面 | 嗅觉(香)→ 视觉(画面) | 赋予视觉以嗅觉的丰富感 |
- “a loud color”(响亮的颜色 → 听觉 → 视觉)
- “velvety voice”(丝绒般的声音 → 触觉 → 听觉)
- “bitter cold”(苦寒 → 味觉 → 触觉)
这些联觉除了来源于人类大脑的机制(跨模态的自动感知耦合),还有强大的文化背景,我们能很容易地将联觉应用到对现实的描述,甚至成为人类想象力的重要来源之一,语言表达中也有大量联觉的体现。
3.巴甫洛夫经典条件反射实验
实验内容:
- 基线测试:单独呈现铃声(中性刺激),狗不分泌唾液或反应微弱;单独呈现食物,狗自然分泌大量唾液(这是无条件反射)。
- 配对训练实验:在每次喂食前,先摇铃(中性刺激),紧接着给予食物(无条件刺激)。铃声与食物在时间上紧密伴随(通常铃声先于食物数秒)。
- 结果测试:经过多次重复配对后,单独摇铃(不再给食物),狗听到铃声也会分泌大量唾液。
- 消退 (Extinction):如果铃声响后长期不给食物,狗对铃声的唾液分泌反应会逐渐减弱直至消失。
- 自发恢复 (Spontaneous Recovery):消退一段时间后,再次呈现铃声,狗可能又会分泌唾液(虽然量较少)。
- 泛化 (Generalization):狗不仅对特定的铃声反应,对类似的声音(如蜂鸣器、特定音调)也会产生反应。 “望梅止渴”也是一个典型的巴甫洛夫反射实验。
这表示神经具备可塑性,大脑并没有长出新的器官,而是通过改变现有神经元之间的连接强度(突触可塑性),让一个原本无关的信号(铃声)获得了激活生理反应(流口水)的“钥匙”。也揭示出,大脑建立了一个预测控制系统。它不再等待环境刺激发生后再去反应,而是利用过去的经验(铃声预示着食物),提前构建了一个关于未来的“模拟场景预测”,并让身体机能做好准备。这至少表明预测编码机制(预测编码理论是大脑可能存在的一种学习机制,虽然并不是全部机制。另外大脑的可塑性,是我们的基本常识,因为AI的出现,也映照出人类的独特之处。
4.强化学习中的时序差分误差(TD error)
在传统的监督学习中,误差通常是 “预测值 vs 真实标签”。但在强化学习中,我们往往没有最终的“真实标签”(因为游戏还没结束,不知道最终总分是多少)。
TD 方法的巧妙之处在于,它用“两个预测值之间的差”来作为误差:
- 预测 1:当前时刻对未来的估计 $V(s_t)$ 。
- 预测 2:下一时刻 $t+1$ 对未来的估计(加上即时奖励) $r_t+γV(s_t+1)$ 。这里的 $r_t$ 就是在 $t+1$ 时刻,我们其实就已经知道上一个时刻 $t$ 的真实值,然后这个真实值加到 $t+1$ 时刻的预测上,就是 $t+1$ 时刻对未来的预测值。
预测 1与预测 2的差值就是需要优化的目标。
1
TD Error = 预测 2 - 预测 1
这样来看,TD Learning 本质上就是一种“随机近似”的卡尔曼滤波,或者说,卡尔曼滤波是 TD Learning 在线性高斯系统下的最优解析解。
TD Learning 和Kalman 滤波共享同一个核心机制:“预测 - 校正”循环(Predict-Correct Cycle),两者的底层哲学都是贝叶斯推断 (Bayesian Inference) 的动态形式:
1
2
3
a.先验 (Prior):我相信世界是这样的X,也就是信念下的对未知的预测。
b.似然 (Likelihood):我观测到了新的真实数据 z。
c.后验 (Posterior):结合预测X和观测z,对未知依然还是会有预测,并构造error,进而更新我的信念。
5.感官替代
经典实验:Tactile-Visual Sensory Substitution (TVSS)
paper:
Vision substitution by tactile image projection. Science, 163(3874), 1468–1470. https://www.nature.com/articles/221963a0
Bach-y-Rita, P. (1972). Brain Mechanisms in Sensory Substitution. Academic Press.
Sadato, N. et al. (1996). Activation of the primary visual cortex by Braille reading in blind subjects. Nature, 380, 526–528.
研究背景:由 Paul Bach-y-Rita 在 1960 年代末开创。这是感官替代领域的奠基性研究。
装置原理:受试者(通常是盲人)背部皮肤上放置一个由数百个微小振动器组成的矩阵。一台摄像机捕捉眼前的画面,将图像的亮暗转换为振动的强弱,将图像的空间位置对应到矩阵的相应位置。
科学发现:
- 行为学:经过 20-40 小时的训练,受试者不仅能分辨线条、几何形状,甚至能识别物体轮廓、判断距离,甚至躲避迎面飞来的球。
- 神经机制:fMRI 扫描显示,当盲人使用该设备时,其视觉皮层(Visual Cortex)竟然被激活了。这证明了大脑并非天生只能用“眼睛”看,只要有空间结构信息输入,视觉皮层就能对其进行处理。
The vOICe 系统
paper:
Meijer, P. B. L. (1992). An experimental system for auditory image representations. IEEE Transactions on Biomedical Engineering.
原理:由 Meijer 在 1992 年开发。它将图像的 X 轴(水平位置) 转换为时间(从左到右扫描),Y 轴(垂直位置) 转换为频率(高低音),亮度 转换为音量。
科学依据:研究发现,经过长期训练的使用者,其大脑的外侧枕叶皮层(通常处理视觉身体形态)会对通过声音传递的人体轮廓产生反应。这意味着大脑学会了从声音流中提取视觉形态信息。
这些都揭示: 1.大脑皮层是“任务组织”的,而非一对一“感官组织”的; 2.大脑具有高度跨模态可塑性:当某个感官缺失时,其对应皮层会被其他感官“接管”。 进一步科学研究发现:背侧顶叶-前运动网络构建身体中心的近体空间表征,并将不同模态输入映射到统一坐标框架中;在视觉缺失条件下,该网络增强对听觉和触觉输入的利用。
paper:
Rizzolatti, G., Fadiga, L., Fogassi, L., & Gallese, V. (1997).The space around us. Science, 277(5323), 190–191.
Graziano, M. S. A., & Gross, C. G. (1995). The representation of extrapersonal space: a possible role for bimodal, visual-tactile neurons. Journal of Neurophysiology, 74, 751–761.
Brozzoli, C., Makin, T. R., Cardinali, L., Holmes, N. P., & Farne, A. (2012). Action-specific remapping of peripersonal space. Nature Communications, 3, 1–7.
6.多模态模型中常用的类Q-Former网络是在干什么?
AI多模态模型中,针对文本,视觉,语音等不同模态,所做的工作是对齐,但是这个对齐侧重映射对齐,而不是统一抽象基准空间的对齐。也就是,文本和视觉对齐,并不是找到第三个统一抽象表示,把文本和视觉放在这个统一抽象表示上,而是在文本和视觉直接建立映射对齐。
例如:Q-Former+LLM,训练Q-Former产生出能让LLM看得懂的视觉表征.具体就是: Q-Former 训练的第一步,将 Q-Former 连接到冻结参数的图像编码器,并使用图像-文本对进行预训练,那么这一步的目标是训练好 Q-Former,以便 Queries 可以学习到如何更好地结合文本提取图片信息。Queries本质上是一个跨模态特征选择模块,通过多任务联合训练,动态筛选并抽象出与文本任务相关的视觉语义。
其核心价值在于:在冻结预训练单模态模型的前提下,仅通过轻量化的Q-Former(约200M参数)即可实现高效的视觉-语言对齐。这种设计平衡了模型性能与计算效率,是多模态预训练领域的重要突破. 属于静态的翻译字典:训练好后映射关系固定。最多再进行一次指令微调,让其适应具体多模态任务上更好一点。
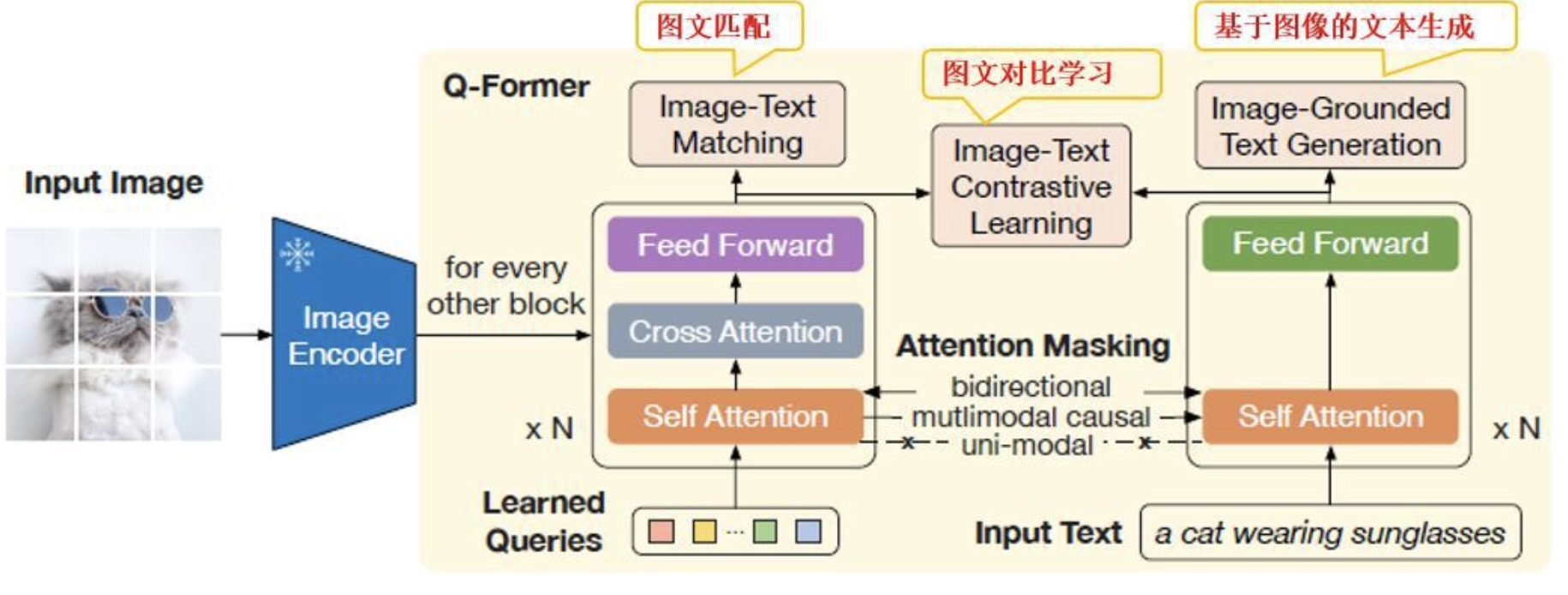 然而大脑是通过背侧皮层(RL 区域)构建统一的抽象空间表征(近体空间)。动态的解码器:能根据环境实时调整映射策略(如从视觉切换到听觉)。所以很明显,现在的多模态模型,既不是感官替代,也没有联觉表现,仅仅只是模态映射对齐。这会导致以下问题:
然而大脑是通过背侧皮层(RL 区域)构建统一的抽象空间表征(近体空间)。动态的解码器:能根据环境实时调整映射策略(如从视觉切换到听觉)。所以很明显,现在的多模态模型,既不是感官替代,也没有联觉表现,仅仅只是模态映射对齐。这会导致以下问题:
1
2
3
a.文本中心主义,所以目前多模态的核心依然是LLM,很明显,人类智能不只是依靠语言。
b.只能建立相关性,难以建立因果性。
c.对齐幻觉持续会存在,对齐很明显不是无损映射,且其对齐先验是LLM。 结合对人类大脑的认知,很明显目前的AI只是模仿了很少一部分,这部分主要局限在大脑皮层的部分模拟。
一个不成熟的猜想:人类大脑依是未来AI发展启发的来源,并且反过来,AI的研究,也能启发对人类大脑的认知。