学习笔记:Diffusion 直接预测干净图片(JiT)
1. diffusion模型长期以来的共识
我们在模型角度,一直是在学习添加的噪声分布,但是回归本质,diffusion模型目标是什么?我们真的需要让模型去预测“噪声”吗?
我们一直认为:预测噪声和预测图片在数学上是等价的,可以相互转换。然而在某些情况下是不等价的,特别是扩散模型中。
在此就有一个疑问:
传统图像去噪算法例如BM3D,DnCNN等大部分其实都是在预测噪声的分布,为什么好像很有效呢?
原因是:传统的图像去噪和diffusion中的图像去噪,所面对的噪声水平是不一样的。传统去噪信息主体还是图像本身,噪声只能算作信息扰动。Diffusion 训练过程是从不同噪声强度(最强到纯噪声中)的 $z_t$ 推断图像信息(或噪声)。
2. 理论基石-流形学习
流形学习的基本假设是:很多现实世界的高维数据,其实是由一个低维流形撑起来的。 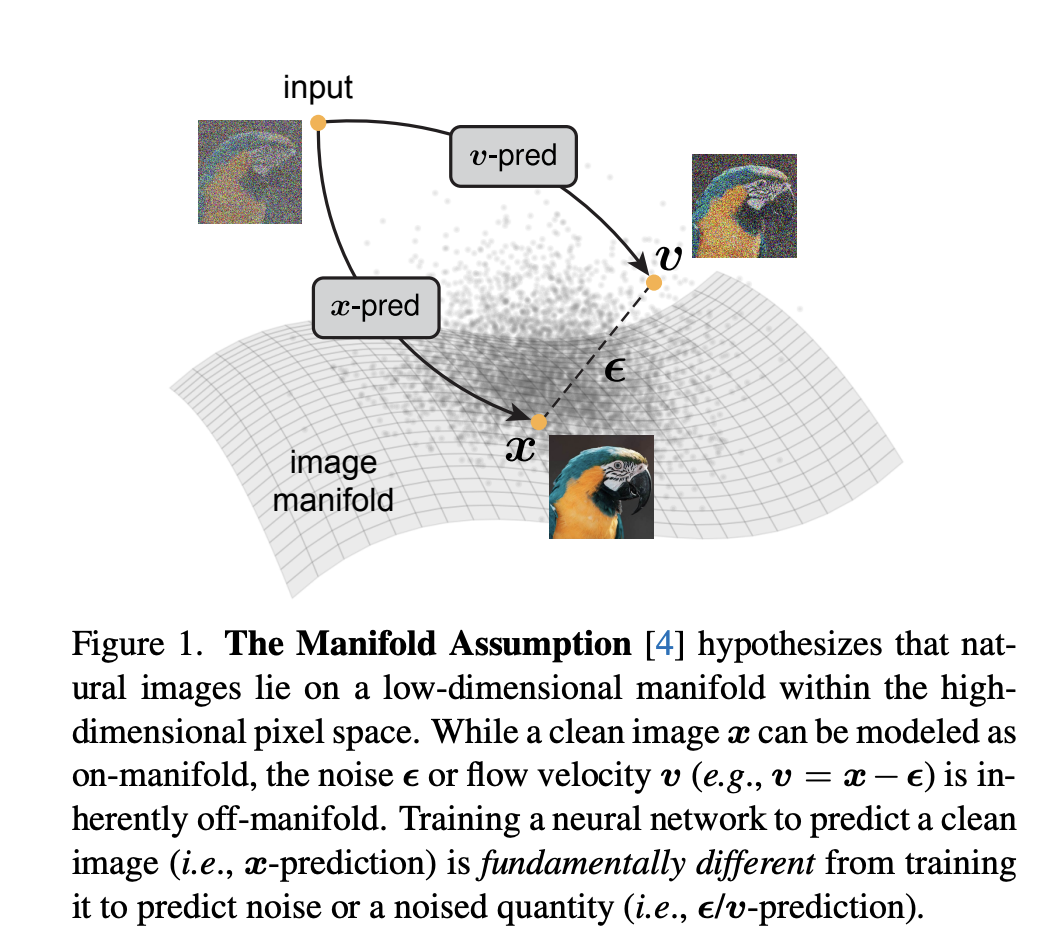
- 干净图像( $x$ ):位于这个低维流形上,结构性强。
- 噪声( $ε$ ):完全是高维空间中的混合强度的随机扰动,不遵循任何流形结构。
- 流速( $v$ ):$v=x-ε$, 作为图像和噪声的组合,同样是“越界”的,处于流形之外。
神经网络去预测一个“在流形上”的目标(干净图像),和预测一个“在流形外”的目标(噪声或流速),是两个难度完全不同的任务。 真实世界的数据是有结构的,它们聚集在一个低维流形上。而噪声是完全随机、高维的。
结构性信息的学习难度要比非结构完全随机、高维学习难度更低。(记忆有规律的一串数字,比记忆完全随机的一串同样长度的数字难度大),在此,又有一个问题:我们不是已经假设Diffusion模型所添加的噪声是高斯噪声,并不是随机无结构噪声吗?
原因是:Diffusion的学习核心是噪声中映射图像信息的过程,而不是仅仅估计高斯噪声参数,从纯噪声中推断图像信息的难度极大。也就是逆扩散:从 $x_t$ 预测 $x_0$ ,当 $t$ 很大时,$x_t$ 几乎全是噪声(接近纯高斯),“高噪声 → 原图”的映射难度极大。
3. 为什么 latent diffusion(如 Stable Diffusion)效果比pixel space diffusion好?
1)将像素空间降维到 latent space,使噪声的维度极大降低,latent diffusion 成功的关键原因是它避免了“高维噪声预测”这个根本困难任务。
2)而pixel space diffusion 不够强大,只能在U-net上通过skip connection 将结构化信息进行复制,从而缓解网络容量不足的问题。
4. JiT(Just image Transformers)
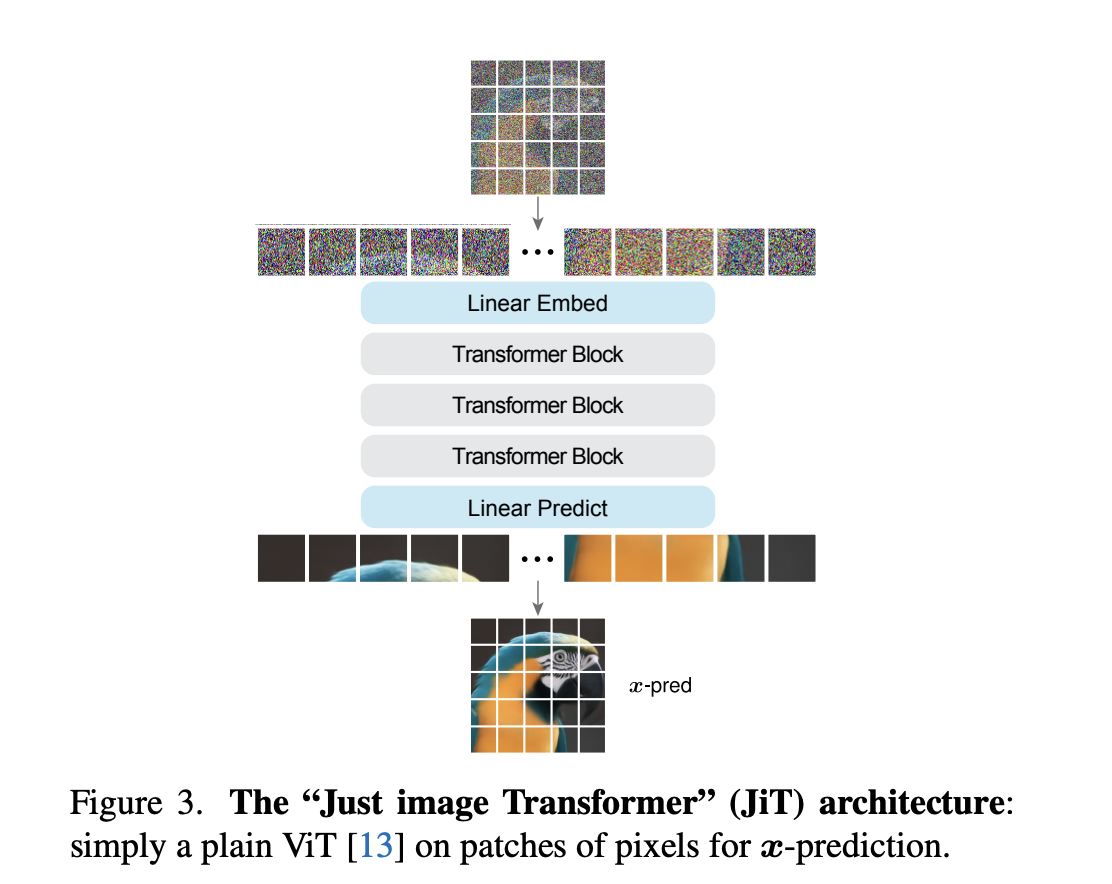
INPUT: 一个加噪的图片 $z_t$:这是由一张真实的、干净的猫的图片 $x$ 和一个随机高斯噪声 $e$ 混合而成的。混合比例由时间步 $t$ 决定。
(1) 分块 (Patching):
将输入的 256×256 图像切分为 16×16 的网格,每个块都是一个高维向量(16×16×3 = 768 维)。
(2) Embedding:
将每个 768 维的图像块向量通过一个线性层投影成一个 Token。
在这里加入一个瓶颈结构(先从 768 维降到 128 维,再升回 768 维)效果更好。
这也是流形学习的重要结论:流形学习方法利用 瓶颈结构 来鼓励只有有用的信息通过。
因此,Latent Diffusion Models (LDMs) 可以看作是 流形学习 + 扩散去噪。
(3) Transformer block:
输入到一个标准的 Vision Transformer 网络中。网络会像处理语言句子一样处理这些图像块序列,并通过 attention 机制捕捉它们之间的关系。
(4) 预测 (Prediction):
Transformer 的输出 Token 经过一个最终的线性层,被解码回 256 个 16×16 像素的图像块。
OUTPUT :
解码后的图像块拼接起来的 256×256 的原始的、干净的图像。
虽然模型的输出是 $x$-pred,但论文发现使用 $v$-loss进行训练效果最好。 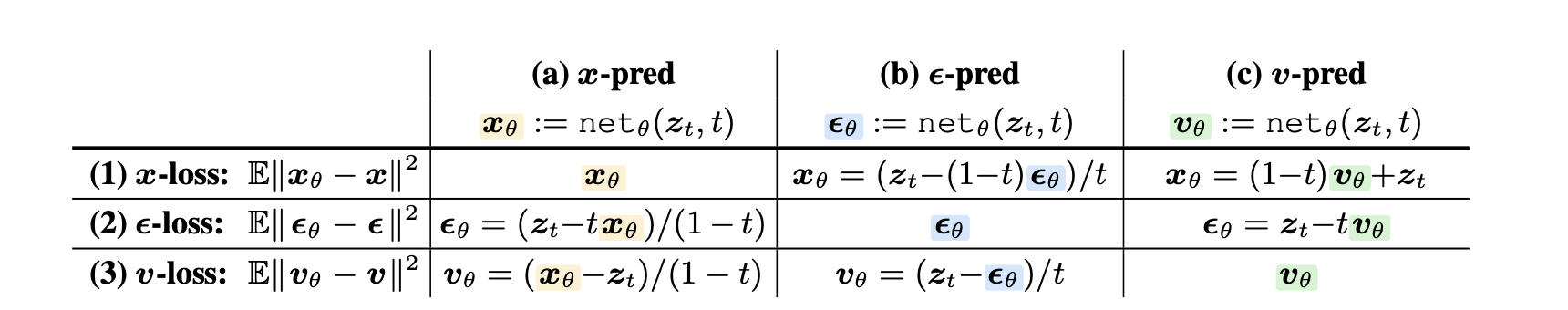

- 根据模型预测的 x_pred 和输入的 z_t,计算出预测的速度v_pred。
- 根据真实的干净图像 x 和输入的 z_t,计算出真实的速度v_truth。
- 计算v_pred和v_truth之间的差距(均方误差),并用这个误差来更新模型的权重。
因此我们可以看见无分词器(tokenizer),无预训练,无额外损失函数。这种简单性与当前主流的复杂模型(如DiT、LDM)形成了鲜明对比,后者通常依赖于强大的VAE、预训练权重或复杂的网络结构。
5. Toy Experiment
一个小实验展示x-prediction的优势:
实验内容:将一个二维的螺旋线数据(低维流形),通过一个随机投影矩阵“埋”入一个更高维的D维空间中。然后,在D-dim空间训练一个简单的生成模型(具有256-dim的5层ReLU MLP隐藏的单元),在这个高维空间里生成数据。 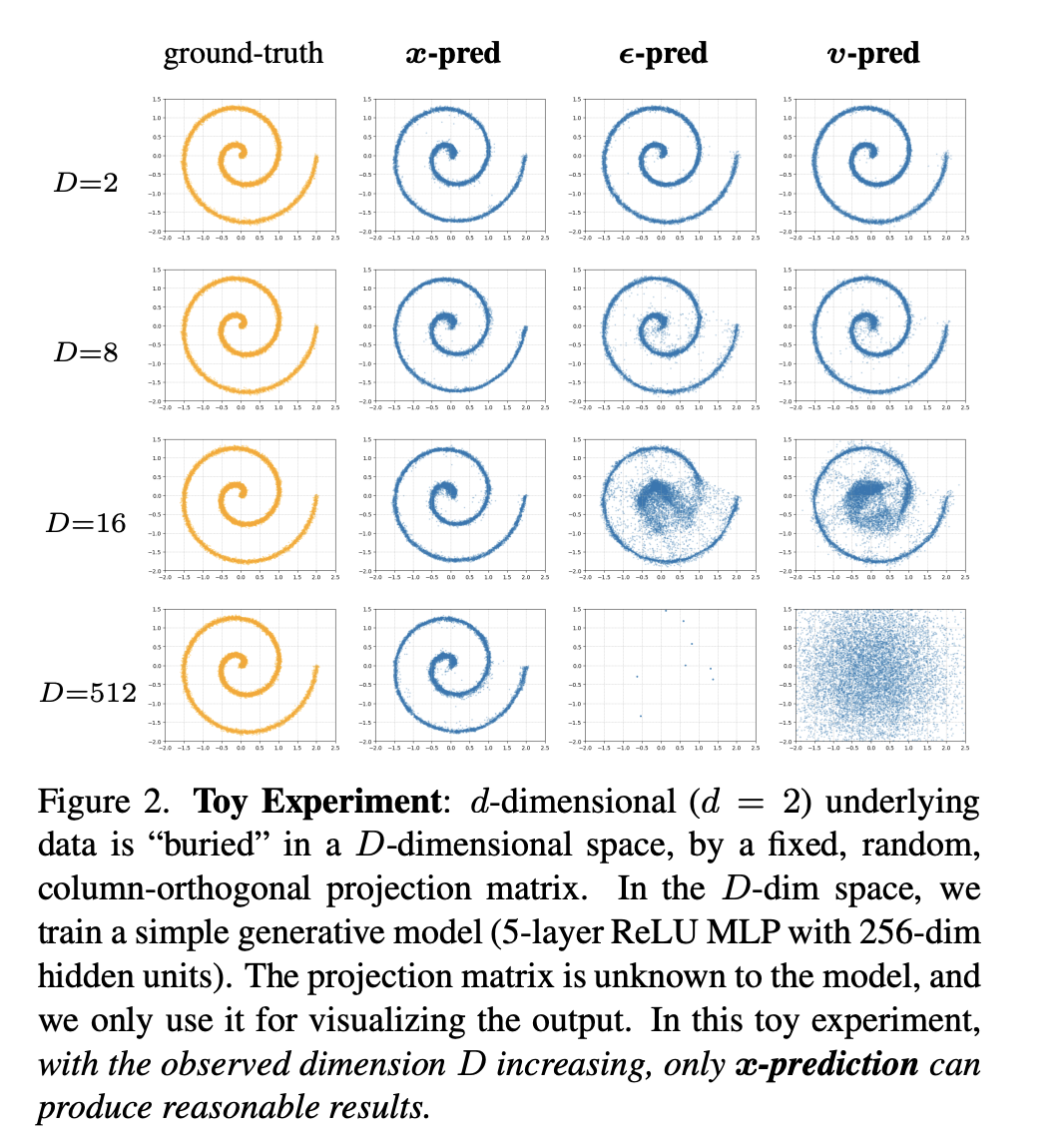
结论:
当观测空间的维度 $ D $ 从 2 增加到 512 时:
x-prediction:始终能完美地恢复出原始的二维螺旋线。即使在 $ D = 512 $ 时,一个只有 256 维隐藏层的“能力不足”的 MLP 也能成功,因为它只需要学习输出那个低维的流形数据。
ε-prediction 和 v-prediction:随着维度的增加,性能急剧下降。在 $ D = 512 $ 时,它们彻底失败,生成的图像一片混乱。这是因为它们被迫在一个高维空间中去拟合无结构的噪声,这对网络容量提出了苛刻的要求。
6. 结果对比
1)对比一:图像生成FID对比
在ImageNet 256x256分辨率上,使用JiT-B/16模型(patch size为16,每个patch的维度是 ,正好等于模型隐藏层的维度)测试了所有9种“预测-损失”组合。此时,每个patch的维度是 ,正好等于模型隐藏层的维度。 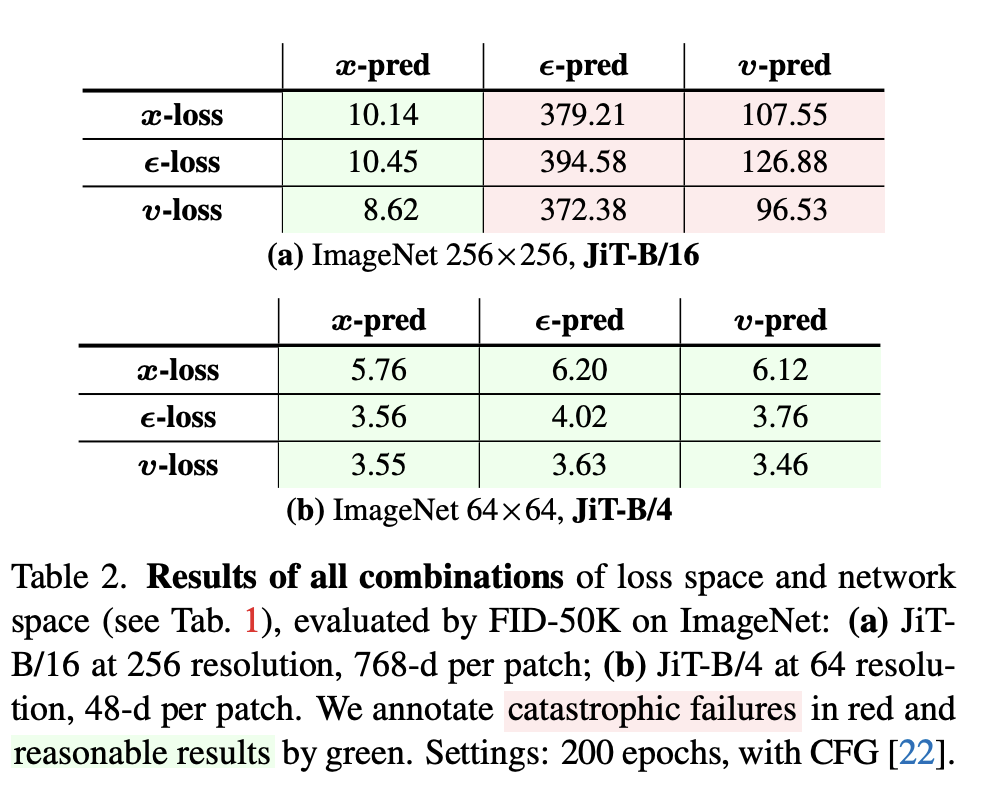
A. 在 256×256 图像中,所有采用 x-prediction 的组合都取得了优异的 FID 分数(最低 8.62),见表 (a)。
B. 当 patch 维度远小于模型隐藏层维度时(如上表 (b),在 64×64 图像上使用 4×4 patch,维度仅为 48,JiT-B 中隐藏层大小为 768),所有组合都能正常工作。
这也解释了为什么在低分辨率数据集(如 CIFAR-10)或使用强力 VAE 降低维度的潜在扩散模型中,这个问题没有暴露出来。
2)对比二
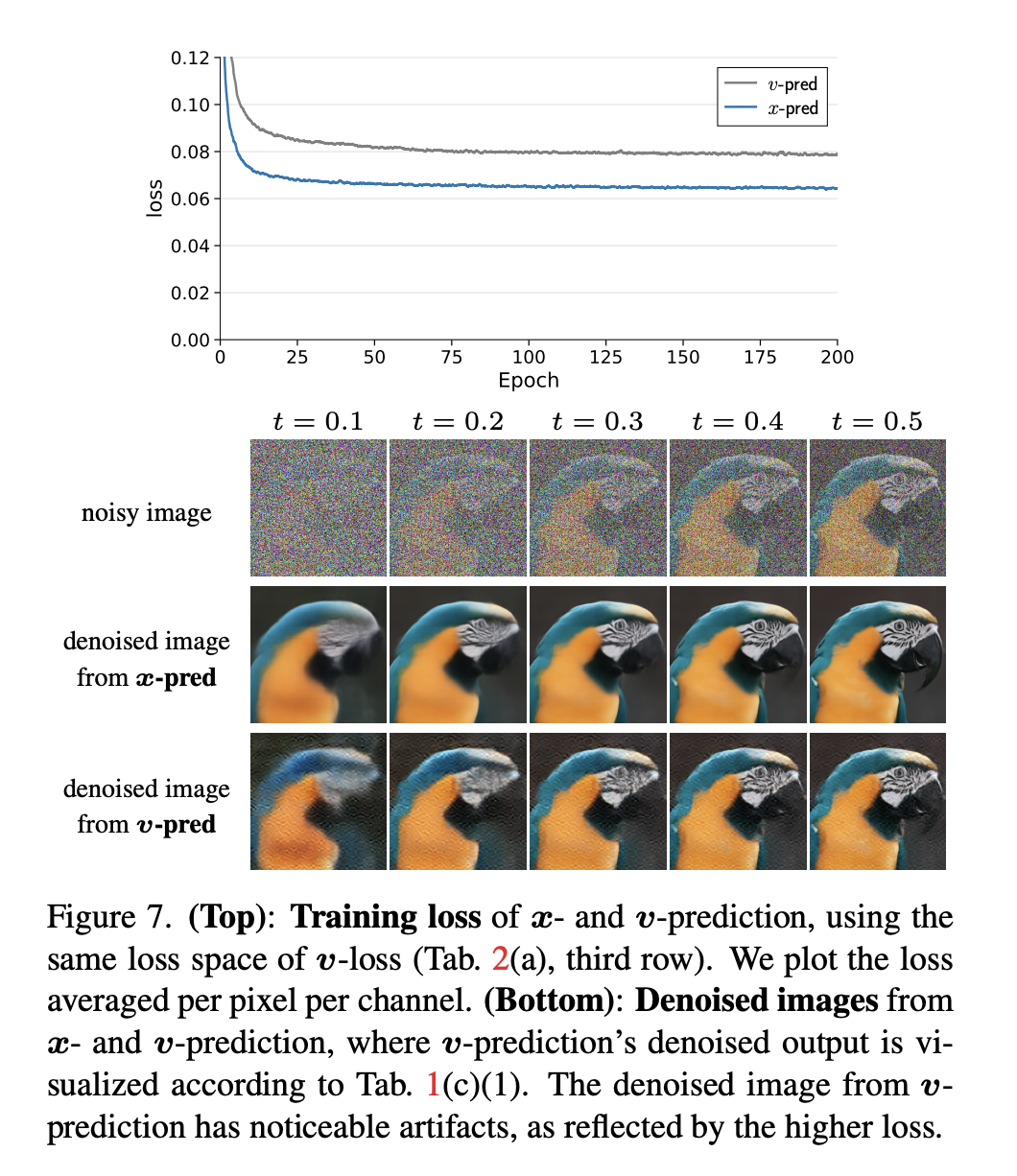
上图展示了x-prediction和v-prediction在训练过程中的差异。使用相同的v-loss,v-prediction的训练损失(上图顶部曲线)远高于x-prediction,并且其单步去噪后的图像(上图底部右侧)也出现了明显的伪影。
3)对比三
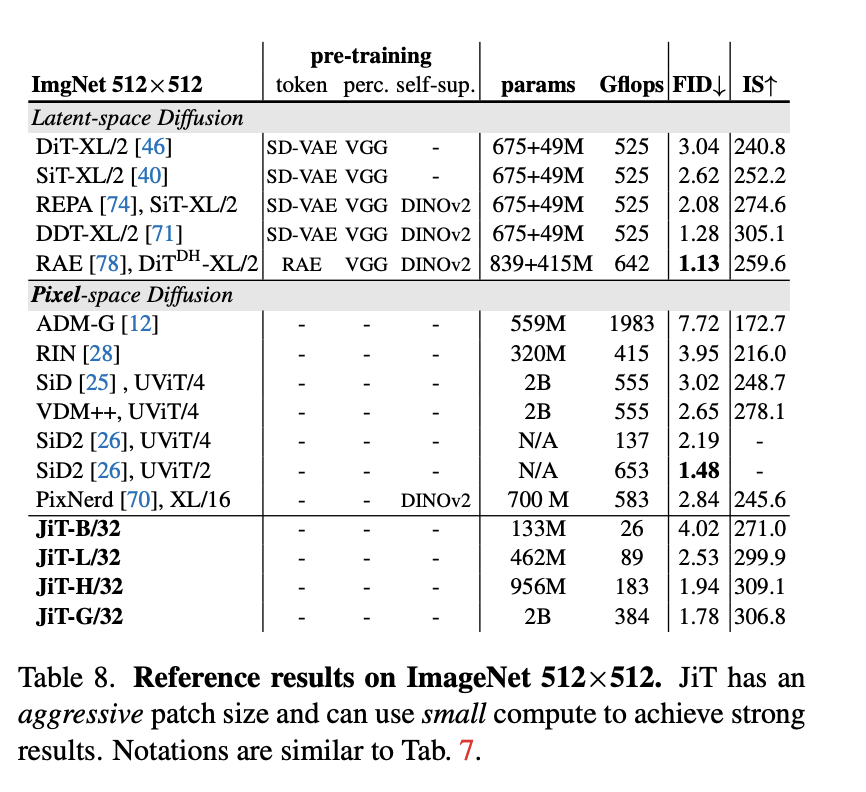
下面是JiT与其他SOTA模型在ImageNet 256x256和512x512分辨率下的比较: 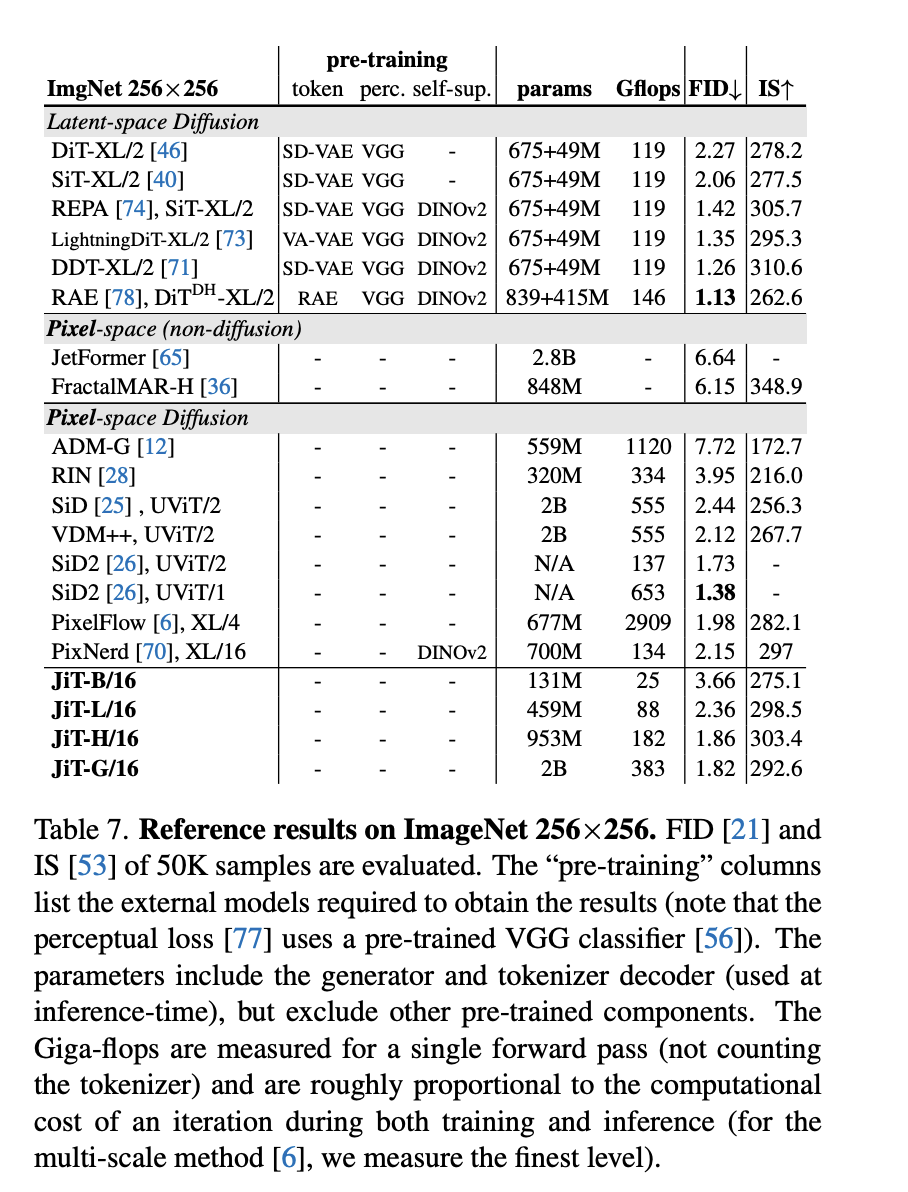
1
2
3
4
5
6
7
8
a. 在ImageNet 256x256基准上,最大的JiT-G/16模型经过600个epoch的训练,
取得了FID 1.82的优异成绩,完全可以与DiT、SiT等依赖复杂的SOTA模型相媲美。
b. 在ImageNet 512x512基准上, JiT在不使用任何预训练、额外损失或复杂技巧
的情况下,取得了与依赖复杂组件的潜在扩散模型(LDM)和像素空间模型相媲美的
结果。例如,在512x512分辨率下,JiT-G/32的FID达到了1.78。
c. JiT的计算成本极低。由于其简单的架构和对大patch的有效处理,其Gflops
(每秒十亿次浮点运算)远低于其他像素空间模型,甚至低于许多潜在空间模型,
这使得JiT在训练和推理上都更加高效。
7. 启发
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
核心依赖是“流形假设”(即数据主要在低维流形上)。如果某些数据不十分符合这一假设(或者噪声与数据结构更复杂地交织), JIT可能就效果不好了。
1). 实际工作的一个新思路
虽然JiT没有很对每一个流程进行精细化的设计,后续还有很多地方需要优化的空间。
但是对未来基于diffusion的图像生成,提供了一个结构简单,计算轻量,效果还不错的新思路。
2). AI 更擅长学习低维流形,而不是高维空间
神经网络表示高维噪声能力是受限制的,但可以很好表示低维信号。
学习的目的是在高维噪声空间中寻找低维信号。
3). 随机噪声的不可压缩
构建latent空间的过程,是对低维信号进行压缩,对高维噪声直接抛弃。
4). AI模型的高维空间与低维特征嵌入(embedding)
任何一个AI模型都是构建在高维空间之上,才能实现特征可分离,学习过程的核心又是捕捉低维流形。
高维空间提供了全备自由度,而同时保持局部自由度和全局结构的低维流形,必须在高维空间内嵌入(embedding),才能表示其拓扑,曲率等复杂信息。